Fonctionnement
du simulateur socio-fiscal
À quoi sert le simulateur ?
Le simulateur socio-fiscal permet d'estimer les impacts d'une réforme paramétrique sur les impôts, les cotisations et les prestations sociales à destination des ménages.
Cet outil permet aux utilisateurs :
- d'estimer, en moins d'une minute, l'impact financier sur des ménages types configurables ;
- d'obtenir l'impact sur les recettes de l'État et de la Sécurité sociale et plus généralement sur la population française, d'une évolution de l'impôt sur le revenu, de la CSG prélevée sur les salaires et retraites et des allocations familiales.
Des impacts sur cas-types
Un cas-type est un cas simplifié d'une situation individuelle, par exemple
: "un foyer composé de deux adultes et d'un enfant, ayant 1 Smic par
mois".
Le simulateur permet de visualiser l'impact du système socio-fiscal français,
c'est-à-dire les cotisations, les impôts et les aides qui concernent ces ménages
types.Voir les 250 dispositifs disponibles
Des situations simplifiées à mettre en perspective
Les estimations sur cas-types sont plus précises que les estimations d'impacts globaux sur la population française, qui eux, dépendent des données disponibles. En revanche, du fait de leur caractère simplifié, elles sont à mettre en perspective avec la réalité du terrain :
- Premièrement, en regard de leur proportion dans la population réelle
difficile à évaluer : Par exemple, l'utilisateur crée deux cas types très simplifiés, l'un
représentant un salarié du privé gagnant le SMIC, l'autre
représentant un salarié du privé gagnant 6000 euros par mois. Les
deux cas types sont affichés à l'écran, pourtant l'un regroupe une
situation simplifiée représentative de beaucoup de salariés, l'autre
concerne une situation bien moins étendue. Plus l'utilisateur configure son cas type en détail, moins il est évident
de savoir combien de personnes réelles peuvent être associées à ce cas type.
Depuis 2024, LexImpact propose une bibliothèque de cas types préconfigurés classés par décile de niveau de vie, permettant de mieux appréhender la réalité de la population française.
- Deuxièmement, il n'est pas possible d'apparenter une estimation d'un cas-type à une situation individuelle précise. Pour cela, il faudrait renseigner l'ensemble des paramètres ayant une influence sur le dispositif à évaluer concernant une personne réelle, à l'instar des déclarations de revenus, et les simulateurs LexImpact n'ont pas cette vocation.
Des impacts globaux
En plus des impacts sur cas-types, le simulateur socio-fiscal LexImpact permet d'estimer les effets globaux d'une modification de la loi. Pour cela, le simulateur s'appuie sur des données représentatives ou exhaustives de la population française :
- Enquête Revenus Fiscaux et Sociaux (ERFS-FPR) de l'Insee (millésime 2023)- Données protégées 🔐 ;
- Déclarations d'impôt sur le revenu des foyers fiscaux (POTE) du Ministère des Finances (DGFIP) (millésime 2023) - Données protégées 🔐.
Le simulateur calcule les impacts globaux, toute chose égale par ailleurs. C'est-à-dire que le simulateur ne prend pas en compte les réactions des agents économiques à la réforme. Par exemple, si une réforme fiscale augmente un impôt sur une catégorie de ménages, le simulateur ne prend pas en compte le fait que les ménages pourraient essayer d'éviter d'entrer, ou au contraire essayer de sortir de cette catégorie, pour éviter cette hausse d'impôt.
2. Mécanique du simulateur
Pour que le simulateur puisse proposer des estimations sur cas types et budgétaires, différentes briques techniques sont nécessaires :
- Les données représentatives de la population française
- Le moteur de calcul
- L'interface utilisateur
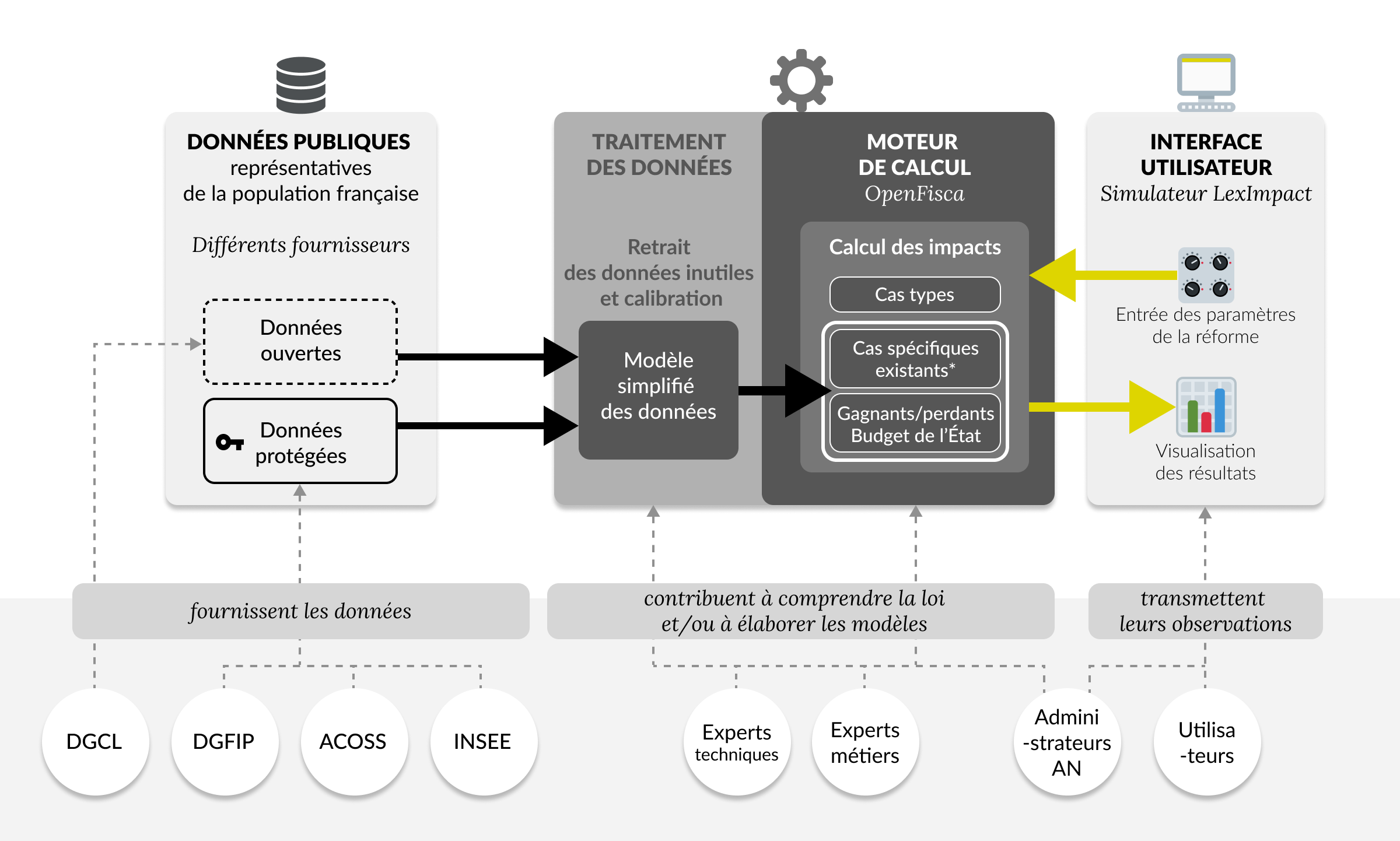
* Le calcul d'impact sur des cas spécifiques est possible uniquement pour des entités dont les données sont entièrements publiques. Actuellement, seul le simulateur “Dotations aux communes” est concerné par les cas spécifiques des communes de France. Cela n'est pas possible pour les entreprises et les foyers fiscaux, dont les données sont protégées.
Un fonctionnement possible grâce à plusieurs acteurs
LexImpact bénéficie d'un écosystème composé de plusieurs acteurs :
- En amont, les fournisseurs de données. Qu'il s'agisse de données publiques, ou de données protégées, cet écosystème est indispensable pour permettre d'estimer les impacts d'une réforme sur la population française et sur le budget de l'État ou de la Sécurité sociale.
- Autant pour le traitement des données que pour le moteur de calcul,
LexImpact échange régulièrement avec des experts techniques et métiers dont le domaine de compétences est reconnu. L'ensemble de ces contributions
est visible dans notre code source
. Les administrateurs de l'Assemblée nationale contribuent par leur expertise des questions juridiques, financières et économiques. - Enfin, le simulateur, comme l'ensemble des outils LexImpact, repose sur
l'analyse des besoins utilisateurs et sur
la prise en compte de leurs retours, dans une logique d'amélioration
continue. Les statistiques d'usage des produits sont disponibles ici
.
Le traitement des données
L'Enquête revenus fiscaux et sociaux (ERFS) produite par l'INSEE est la base de données centrale pour nos simulations budgétaires. Il s'agit d'un échantillon de 50 000 ménages représentatif de la population française. La taille de la base de données, plus petite que des données exhaustives telle que POTE, permet une plus grande rapidité de calcul. L'utilisation de la version FPR de la base nous permet de connecter la base au simulateur en ligne, ce qui ne serait pas possible avec la version ERFS (sans FPR) qui est accessible uniquement via le Centre d'accès sécurisé aux données (CASD).
L'ERFS-FPR n'est pas utilisée telle quelle dans la simulation, elle passe par plusieurs étapes de retraitement afin d'être plus adaptée :
- Augmentation de la précision des revenus : Afin d'augmenter la précision des informations concernant certaines catégories de revenus (les revenus du capital principalement), les données de l'ERFS-FPR sont complétées par des données issues de la base exhaustive POTE. Par exemple pour avoir plus de détails sur la répartition entre différentes catégories de revenus du capital, répartition qui a un impact non-négligeable sur l'impôt calculé.
- Mise à jour : Le millésime de l'ERFS-FPR dont nous disposons une année donnée concerne les revenus de quelques années auparavant. Les données sont donc mises à jour (vieillies) afin de se rapprocher de la situation de l'année en cours. Par exemple les revenus sont inflatés.
- Calibration : Enfin, au vu de l'ensemble des hypothèses de calcul faites lors de la génération de la base, sa pertinence est vérifiée en effectuant plusieurs calculs et en comparant les résultats du simulateur aux chiffres officiels. La base est ainsi re-calibrée jusqu'à l'obtention de résultats pertinents pour tous les types de calculs.
L'ensemble de ces étapes est détaillé dans notre documentation
technique :
Documentation technique
Le moteur de calcul
LexImpact utilise le calculateur OpenFisca
Logiciel open-source et collaboratif, OpenFisca été créé en 2011 au sein de France Stratégie en partenariat avec l'Institut d'économie publique (IDEP) afin de permettre une plus grande transparence de la législation fiscale et sociale et une meilleure appréhension de celle-ci par les citoyens. Aujourd'hui, il est utilisé par différents organismes, tels que l'ANCT (Agence nationale de la cohésion des territoires), la direction de la sécurité sociale, l'IPP (Institut des politiques publiques), Beta.gouv (service rattaché à la direction interministerielle du numérique- DINUM), et est développé, mis à jour et vérifié par des contributeurs du monde entier.
3. Fiabilité des résultats
Méthodologie de vérification des résultats
Plusieurs mécanismes sont en place pour s'assurer de la qualité des résultats :
- Mise au point des algorithmes sur des petits jeux de données : Pour mettre au point les algorithmes, la cellule LexImpact gère manuellement des jeux de données de test idéaux pour confirmer que l'algorithme produit bien le résultat attendu par la théorie.
- Tests avec des données que l'on connait déjà : Ensuite, il est demandé à l'algorithme de produire des données que la cellule LexImpact connaît déjà. Il est ainsi possible de mesurer l'écart entre les résultats obtenus et la réalité.
- Contrôles des résultats vis à vis d'agrégats : Pour les données dont la cellule LexImpact n'a pas les détails, il est parfois possible d'utiliser des totaux. Par exemple, en août 2021, la dernière enquête ERFS-FPR de l'Insee disponible concernait 2018, mais l'Insee publie également le montant global des recettes de l'impôt en 2020. La cellule a pu utiliser ce chiffre pour vérifier si la somme des simulations pour 2020 s'en rapprochait. Et même l'utiliser pour corriger les données.
- Contrôle des résultats de simulations unitaires : Pour vérifier que les simulations sont correctes, la cellule réalise également des tests manuels sur des cas particuliers. Cela permet de confronter les résultats du simulateur LexImpact à d'autres simulateurs. Il est également possible de comparer les simulations réalisées avec le simulateur LexImpact, et celles effectuées avec OpenFisca directement sur les jeux de données complets auxquels la cellule a accès hors ligne.
- Tests automatiques : LexImpact utilise un systéme dit d'intégration continue. C'est-à -dire, qu'après chaque modification de l'application, des tests automatisées sont exécutés sur l'ensemble de l'application. Cela permet de s'assurer qu'aucun bug n'est introduit lors des évolutions. Cela limite les tests manuels à réaliser et permet de livrer plus rapidement des nouvelles fonctionnalités.
Une marge d'erreur incompressible
Les résultats du simulateur LexImpact ont, comme c'est le cas de tout simulateur, une certaine imprécision. Ils fournissent des estimations. Le calcul d'une marge d'erreur est impossible car l'imprécision provient de l'intrication de différents écarts ayant plusieurs origines :
- La mise à jour du moteur de calcul : Le simulateurs socio-fiscal s'appuie sur un calculateur, OpenFisca
. Celui-ci est codé en langage Python , et ses formules reflètent la loi existante. La législation, en matière fiscale et de sécurité sociale, évoluant au moins tous les ans, il est nécessaire de mettre à jour ce moteur de calcul, en recodant des formules et des paramètres. Cette mise à jour ne débute qu'après publication de la loi au Journal officiel, et nécessite un temps plus ou moins long. Malgré les nombreuses contributions que permet OpenFisca en étant un logiciel libre, la mise à jour est progressive étant donné le large périmètre du modèle. La cellule LexImpact commence par les dispositifs qui pèsent le plus lourd dans les calculs, jusqu'à obtenir des résultats cohérents, mais un petit écart non significatif peut subsister. - La simplification d'une situation : Que ce soit pour le calcul des cas-types ou pour le calcul d'impacts sur la population française, les paramètres définissant l'entité pour laquelle l'impact est calculé sont toujours simplifiés. Dans le cas d'impacts globaux, les données sont parfois simplement inexistantes ; pour les cas types, l'entrée de l'ensemble des paramètres serait extrêmement fastidieuse pour l'utilisateur et représenterait un coût de de développement logiciel très élevé. Par conséquent, pour limiter les développements, limiter le temps de calcul et faciliter le parcours utilisateur, LexImpact prend des valeurs moyennes ou par défaut (souvent zéro) pour toutes les données qui ont un faible poids dans le résultat final. Par exemple, dans le cas du calcul de la CSG d'un ménage au SMIC avec deux enfants, les paramètres tels que les heures supplémentaires, les intérêts perçus sur un PEL de moins de 12 ans, ou encore les titres non côtés détenus dans le PEA, sont mis à 0. L'utilisation de valeurs par défaut ou moyennes génère donc un écart par rapport aux situations réelles individuelles.
- Les données représentatives de la population française : Souvent décalées dans le temps car mises à disposition avec un délai de 1 à 2 ans, les bases de données présentent parfois des erreurs d'entrée, des doublons, des manques, ou tout simplement des biais dans le cas où la base de données est construite à partir d'un échantillon de la population. On parle alors d'erreur de "sample". Comment expliqué dans la partie précédente traitement des données, la cellule LexImpact traite ces informations pour réduire les écarts, mais ce traitement ne permet pas d'obtenir un résultat 100% conforme à la réalité.
Pour réduire les marges d'erreur, la cellule LexImpact travaille en continu à l'amélioration du modèle, échange régulièrement avec des experts. Compte tenu de ce travail de validation, les résulats présentés sont cohérents et permettent de mettre en évidence les effets de différents dispositifs sur des ménages et sur l'État, avec une marge d'erreur raisonnable, mais qu'il faut garder à l'esprit.
Aidez à améliorer LexImpact, n'hésitez pas à contribuer